
Encoding and linguistics
The relationship between encoding and linguistics; and a simple exercise

Overview
This blogpost attempts to explain how encoding is related to linguistics and linguistic theory, and it also includes a short encoding exercise. This article lays the groundwork for a series focused on examining the relationship between linguistics and cybersecurity, where encoding plays an important role.
What is (not) encoding
Encoding is a process of transforming a text (or a set of characters) using different symbols while maintaining the semantics and context identical. The difference is that now people who speak different languages (literally, in this case, who understand a different set of characters/signs to represent language) can understand the meaning.
In computer terms, encoding is the closest thing to translation.
Encoding isn’t ciphering, encryption or hashing: it is not used for hiding information or for signing and verifying data.
With encoding it’s enough to know the scheme (usually one, but you could layer them) that’s used to retrieve or encode the original message. Anyone familiar with the scheme, which may be publicly available or well-known, can decode the message: much like being familiar with various languages. Encoding merely transforms data into a different form that can be used by other systems or people.
Encoding in terms of linguistic theory
In linguistic terms, we could say that encoding works within the realm of the relationship between the “signifier” and the “signified”. Saussure, a Swiss linguist and semiotician, tells us that the signifier (the form of a word or symbol) is distinct from the signified (the concept it represents), and the relationship between the two is arbitrary, i.e. there is no sound symbolism.

Encoding preserves the signified – the underlying data – and transforms the signifier into a different “surface form”. If used repeatedly, i.e. in layers, this creates “distance” between the signified and the signifier (an attempt to break or stretch the relationships in Saussure’s semantic triangle). The “distance” can effectively then be used for obfuscation, evasion or deception. However, as I will show in future articles, it can be equally useful for tracking and attribution of some illicit cyberactivities.
Types of encoding
In cyberspace and cybersecurity, there are many types of encoding; this blogpost gives an overview of four types of encoding:
ASCII
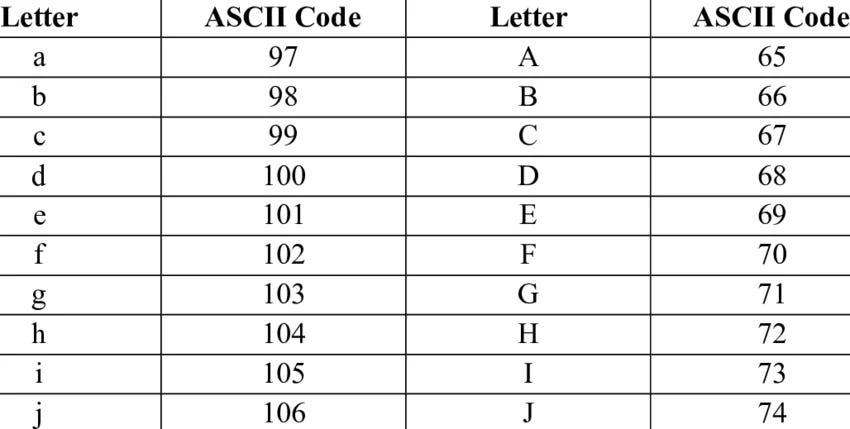
ASCII (American Standard Code for Information Interchange) represents the English language and its characters using numbers between 32 and 127. Different languages also use different code “pages”, or systems, due to the need for different characters (128 to 255), which facilitate multilingual interfaces: for example, while number 101 is the regular “e”, number 130 might be “é”.
ASCII numbers are assigned, for example, as follows in the figure.
Unicode
Unicode is a standard encoding system that assigns a unique value to every character, and this value can be used to represent the character on any system. It allows computers to operate with texts written in different alphabets, writing systems and symbols, without the need for different “code pages” for different languages as in the case of ASCII.
Each character is assigned, or maps to, a unique code point. These code points are labeled as U+, with hexadecimal notation coming after it.
So, if you can’t figure out how to type an en dash in Word, for example, you can always use Unicode. En dash maps to the code point
2013. Type {2013}, and then just press ALT+X.
Joel Spolsky gives a great example on his blog, which I will also use here. If we take a string “Hello”, it maps to five (Unicode) code points, one code point per letter:
U+0048 U+0065 U+006C U+006C U+006F
If we were to store these codepoints (each of them) in two bytes, it would look like this:
00 48 00 65 00 6C 00 6C 00 6F
The problem was that now the first byte was always empty (00), which wasn’t very efficient. That’s why UTF-8 was invented.
UTF-8
Now with UTF-8, every code point is stored in a single byte (no more 00 XX; just XX). Our word “Hello” would be encoded in UTF-8 like this:
48 65 6C 6C 6F
Base64
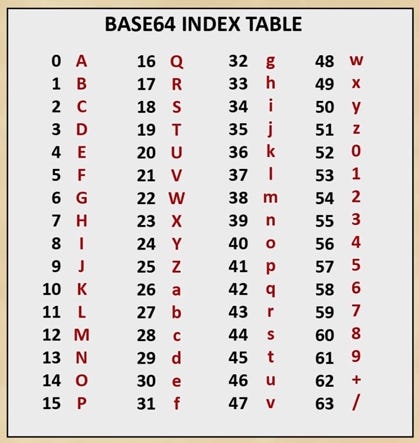
Base64 encoding is widely used, among others, by malware authors to disguise their attacks, complicate attribution and evade analysis tools. “64” refers to 64 characters (mixture of uppercase and lowercase characters, numbers and the equal sign) used for encoding. Note that the number of characters in a base64-encoded string must always be divisible by 4.
Encoding and localization
Unicode, ASCII and UTF give us the possibility to encode information (i.e. characters) in multiple languages, and store and transmit it across systems.
These encoding systems function as a technical layer that maps linguistic signs into machine-readable representations, which can also be useful in translation and localization workflows.
A simple encoding exercise
For the sake of brevity, let’s say we use a simple encoding, based on a pangram (Mr Jock, TV quiz PhD, bags few lynx), to transform my name from ADAMCHRENKO to QOQAENBUYFD.
So we would consider our encoded text as a group of ASCII characters [QOQAENBUYFD]; not much different from “hi” or the original name, although our string makes no direct semantic sense, i.e. it already breaks, to certain extent, the rules of the Saussurean semantic triangle. We would now assign each letter in our newly-formed string an ASCII value. Like so:
Each letter in our string in ASCII (decimal):
Q: 81
O: 79
Q: 81
A: 65
E: 69
N: 78
B: 66
U: 85
Y: 89
F: 70
D: 68
Now we need to convert each letter, i.e. each ASCII number, to 8-bit binary (note that the number of digits in each number corresponds to the number of bits [8]):
81 - 01010001
79 - 01001111
81 - 01010001
65 - 01000001
69 - 01000101
78 - 01001110
66 - 01000010
85 - 01010101
89 - 01011001
70 - 01000110
68 - 01000100
We can write out our message (QOQAENBUYFD) in 8-bit binary:
01010001 01001111 01010001 01000001 01000101 01001110 01000010 01010101 01011001 01000110 01000100
Then, we need to split these into segments of 6 bits (digits, binary) instead of eight. If there are any segments left (not grouped in six), they need to be “padded” by 0s ([two zeros added at the very end of the string]).
010100 010100 111101 010001 010000 010100 010101 001110 010000 100101 010101 011001 010001 100100 010000
We added two zeros (00) at the end of the string for padding, so we will be using (=) at the end of the final base64-encoded string.
If we needed to add four zeros at the end of the string, we would use (
==) at the end of the base64-encoded string.
Now we need to convert each group of 6 bits (binary) into decimal. We can do this manually, by assigning each position from right to left powers of 2 (starting from 0), and by multiplying the powers of 2 by either 1 or 0; then adding the values together. Or we can just use a converter.
The string above (binary in groups of 6 bits) in decimal would look like this:
20 20 61 17 16 20 21 14 16 37 21 25 17 36 16
And now we can use the base64 table from the beginning of the blogpost to find the corresponding symbol to each number (your numbers should be in range from 0 to 51 * for letters).
20- U
20- U
61- 9
17- R
16- Q
20- U
21- V
14- O
16- Q
37- l
21- V
25- Z
17- R
36- k
16- Q
And the base64-encoded string (ADAMCHRENKO transformed to QOQAENBUYFD) would look like this (don’t forget the “=” mentioned above, due to the padding):
UU9RQUVOQlVZRkQ=
Conclusion
Encoding has several important overlaps with linguistics and linguistic theories, as demonstrated by the connection with Saussure’s theory and the relationship he delineates between the signifier and the signified. Encoding is an attempt to break this relationship – at least to a certain extent. Adversaries in cyberspace use these simple encoding techniques to leave messages or create their “MO”; therefore, encoding often serves as a means to identify, track, attribute and cluster cybercriminal activities.